5.2 分区策略设计
从复制组到分区
在"复制"一节中我们确立了复制组的概念——它是分布式存储中最基本的存储单元,负责将用户数据可靠地保存为多份。
但一个复制组的容量是有限的。无论它是 1GB 的 Extent 还是 120GB 的 DataPartition,单个复制组终归存不下整个集群的数据。一旦数据规模增长到 TiB/PiB/EiB,就必须有多个复制组来承载,于是自然而然地引出了一个问题:
用户的数据,应当去往哪一个复制组?
这就是分区策略要回答的核心问题。在笔者工作经历中遇到的这些系统,分区无外乎需要解决三件事:
- 路由:给定一份数据(或其 key, 或者 blob/file id),能快速确定它归属于哪个复制组。
- 均衡:数据和负载在所有节点间尽可能均匀分布。
- 弹性:节点增删时,数据能平滑迁移,不影响在线服务。
这三者互相制约。不同系统在三者之间的取舍,构成了分区设计中最有趣的工程决策。
两大流派
复制篇末尾留下过一个伏笔:
复制组越大,创建越静态,平衡迁移越重。但有一个巨大优势就是路由管理节点就可以很轻,甚至不可用也不影响用户流量。
这句话其实概括了分区设计中最根本的一对矛盾。笔者将当前主流分布式存储的分区策略归纳为两大流派,它们恰好站在天平的两端。
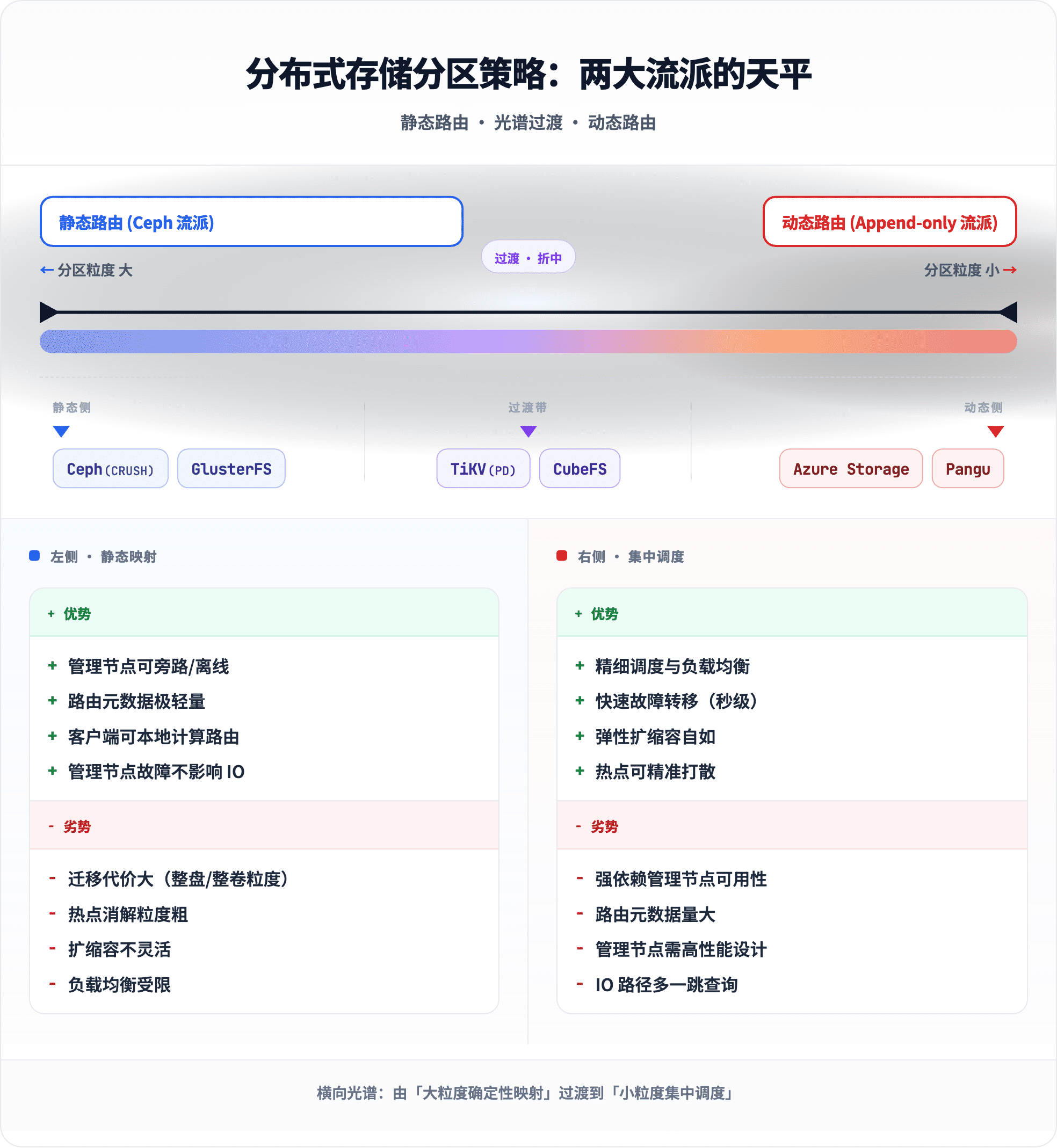
静态路由流派
代表系统:Ceph (CRUSH)。
设计哲学:让客户端自己算出数据在哪,管理节点越轻越好。
具体做法:
- 将物理或逻辑磁盘直接组成复制组(如 Ceph 的 Placement Group)
- 集群维护一份相对稳定的拓扑描述(Cluster Map)
- 客户端拿到 Map 后,通过确定性算法在本地计算出数据的存放位置
- 管理节点(如 Ceph Monitor)仅负责维护和分发 Map,不参与用户 IO 路径
这种设计下,管理节点即使短暂不可用,只要 Map 没有变化,客户端照常读写。对于大规模集群,这意味着极低的管理面风险。
代价:热点、搬迁、均衡的噩梦。:分区粒度是 PG 级别的。一个 PG 内可能装着数万乃至数十万个对象。想要做精细的负载均衡——比如把某一批热点对象单独挪走——对不起,只能整个 PG 搬走。扩缩容时,算法的重新映射也难以做到"只动最少量的数据"。
动态路由流派
代表系统:Azure Storage(Partition Layer + Extent)、Pangu。
这类系统一般是 Append-Only 的存储底座。受这个设计哲学影响,路由的反过来:打造一个强力的管理节点,一切分配和调度决策由它集中执行。
具体做法:
- 分区单元非常小(如 Azure 的 Extent 约 1GB),属于 Append-only 的数据块
- 写入时客户端向管理节点申请分配目标复制组,管理节点返回具体位置
- 故障转移、负载均衡、编码转换等操作,管理节点掌握全局信息后直接下发指令
这类系统的调度灵活性拉到了极致。新节点上线后立刻能分到写流量;某块磁盘出现慢盘,管理节点秒级就能将其上的写流量切走;想把一批冷数据从三副本转 EC?管理节点发一条指令就行。
代价:控制节点的稳定性和性能极度重要。:用户 IO 路径上对管理节点有依赖。管理节点挂了,新的写入就无处可去1。因此这类系统在管理节点的可用性设计上投入极大精力——多副本 Raft、读写分离、多级缓存,一个都不能少。
天平之间
并非所有系统都站在极端。TiKV 和 CubeFS 就是折中派的代表:
- 分区粒度适中(TiKV Region 约 96~144MB,CubeFS DataPartition 约 120GB)
- 有集中式调度节点(PD / Master),但 IO 路径中并非强同步依赖
- 客户端缓存路由信息,仅在 Epoch 失效时回源查询
这种折中方案牺牲了一部分调度的极致灵活性,换来了对管理节点依赖程度的降低。
| 维度 | 静态路由 | 折中 | 动态路由 |
|---|---|---|---|
| 分区粒度 | PG 级(万级对象) | Region/DP 级(百MB~百GB) | Extent/Chunk 级(~1GB) |
| 管理节点角色 | 仅分发 Map | 调度+路由缓存 | 全权分配 |
| IO 路径依赖 | 无 | 弱(缓存旁路) | 强 |
| 负载均衡精度 | 粗 | 中 | 极细 |
| 故障转移速度 | 依赖 Map 更新 | 秒~十秒级 | 秒级 |
| 编码转换难度 | 高 | 中 | 低 |
分区映射策略
流派确定了大方向,但具体用什么算法把 key 映射到分区?
本节不打算重复 DDIA 里的数学推导,从选型逻辑的视角来归纳。
Hash 取模
最朴素的做法:partition_id = hash(key) % N。
均匀性天然有保证。问题在扩缩容:N 一变,几乎所有数据都要重新映射。在早期 Memcached 的一致性问题暴露之前,很多系统这么实现,也没什么问题。
适用场景:分区数量几乎不变的系统,或者愿意承受全量 rehash 代价的离线批处理场景。
一致性哈希与虚拟节点
一致性哈希解决的正是 Hash 取模在扩缩容时"牵一发动全身"的问题。环上增删节点,只影响相邻区间的数据。
但裸的一致性哈希在节点少的时候,分布极不均匀。实际工程中必须引入虚拟节点(VNode):每个物理节点映射为多个虚拟节点散布在环上,粒度越细,均衡性越好。
工程案例:Dynamo、Cassandra。
Dynamo 论文中的经验数据:每个物理节点配置约 150 个虚拟节点时,负载方差降至可接受范围2。
Range 分区
按 key 的范围切段。分区 A 负责 [aaa, bbb),分区 B 负责 [bbb, ccc),以此类推。
最大优势是支持范围扫描。这对数据库类系统至关重要——你没办法在 Hash 分区上高效执行 SELECT * WHERE key BETWEEN x AND y。而 Prefix Range Scan 是很多系统的刚需。考虑一个 S3 存储系统的元数据管理,必须高效支持 ListBucket 操作。
最大劣势是热点。如果 key 是单调递增的(典型的如时间戳),写入永远打在最后一个分区上。解法是分裂:当一个分区成为热点,自动将其一分为二。TiKV 和 HBase 都采用此策略。
CRUSH 类伪随机可计算放置
Ceph 的核心算法。给定 (object_id, cluster_map),CRUSH 能在客户端本地计算出数据归属的 OSD 集合,无需查询任何目录服务。
其本质是一棵加权的 bucket 树 + 伪随机选择函数。改变集群拓扑(加盘、下架)只需更新 Map 并广播,客户端重新计算即可。
局限:
- CRUSH 的均匀性受物理拓扑和权重设置的影响较大,调参不易
- 资源均衡困难——算法的确定性映射与"最优均衡"天然存在矛盾
- 想做到"只搬最少量的数据"需要精心设计 rule,且不总能如愿
控制节点动态分配
这是动态路由流派的映射实现。不存在什么映射算法——数据写入时,由控制节点实时分配去处。
比如 Azure Storage 的写入流程:客户端请求 Partition Layer,Partition Layer 向 Stream Layer 的 Stream Master 申请一个可写的 Extent;Stream Master 根据当前各节点的负载、可用空间、故障域约束,返回一组目标节点。
即使这个 Extent 遇到问题,简单重试后,client 可立即放弃,随后向控制节点申请新的可写 Extent 快速实现故障转移。
优势:极度动态
- 资源池级别的动态均衡:新节点一加入就能被分配写入
- 编码转换容易:控制节点知道全局数据分布,实现 “把这批 Extent 从三副本转 EC(6,3)” 的指令
- 故障转移迅速:某节点不可用,控制节点立刻停止向其分配
劣势:控制节点极其重要
一旦控制节点不可用,新的写入直接瘫痪。因此必须在控制节点上做到极高规格的高可用——Raft 复制、读写分离、客户端缓存兜底、多级 failover。这种流派控制节点的性能和稳定性是重中之重!
选型决策
| 映射策略 | 路由方式 | 范围查询 | 扩缩容代价 | 均衡灵活度 | 代表系统 |
|---|---|---|---|---|---|
| Hash % N | 可计算 | 不支持 | 大 | 低 | 早期 Memcached |
| 一致性哈希 | 可计算 | 不支持 | 小 | 中 | Dynamo / Cassandra |
| Range | 需查目录 | 支持 | 中 | 中 | TiKV / HBase |
| CRUSH | 可计算 | 不支持 | 中 | 低 | Ceph |
| 控制节点动态分配 | 查管理节点 | 可支持 | 小 | 极高 | Azure Storage / Pangu |
映射策略不存在通杀方案。工程选型时,笔者会问自己这些问题:
- 访问模式是否需要范围查询?
- 能否承受集中式管理节点的复杂性?
- 对均衡精度的要求到底有多高?
用户需求不同,选择不同。
分区的生命周期(以 TiKV 为例)
一个活跃的存储系统必然是动态的。数据可能在涨,负载可能在变,分区需要分裂、合并、迁移。TiKV 的分区策略是非常经典可靠的 Range 级别分区。本节以 TiKV 的 Region 机制为例,和读者一起纵览一遍分区的生命周期。
Region 是什么
TiKV 将整个 key space 按范围切分为若干 Region。每个 Region 是一段连续的 key 范围,默认大小约 96~144MB。Region 内部通过 Raft 实现多副本一致性,即每个 Region 就是一个独立的 Raft Group。
PD(Placement Driver)是 TiKV 集群的调度中心,维护所有 Region 的元数据和副本分布信息。
创建
集群初始化时,整个 key space 只有一个 Region。随着数据写入,Region 不断分裂。也可以在建表时预先 split,避免初期的单点热点。
分裂(Split)
触发条件:
- Region 大小超过阈值(默认 144MB)
- Region 的 key 数量过多
- PD 检测到该 Region 是写热点,主动触发 split 以打散负载
执行流程:
- Region Leader 上报心跳时,PD 判断需要分裂
- PD 下发 Split 指令(或 Leader 自行判断后提 Raft 提案)
- Leader 将 split 操作作为一条 Raft log 提交
- 所有副本 apply 后,一个 Region 变为两个,各自拥有独立的 Raft Group 和 Leader
分裂是个轻量操作——不涉及数据搬迁,只是在逻辑上把一段连续 key 范围一分为二。数据还在原来的节点上。
合并(Merge)
大量删除后可能出现很多极小的 Region,浪费 Raft 的心跳和元数据开销。相邻两个 Region 如果都低于阈值(默认 20MB),PD 会发起合并。
合并比分裂复杂:需要协调两个 Raft Group 的 Leader,确保两边状态一致后才能执行。
迁移(Transfer / Rebalance)
目的:均衡各节点的 Region 数量和负载。
PD 的调度器会持续观察各 TiKV 节点的 Region 数量、磁盘用量、读写 QPS 等指标。一旦发现不均衡(如新节点加入后 Region 数为 0),PD 下发调度指令:
- Transfer Leader:将 Region 的 Raft Leader 切换到另一节点。不搬数据,只转移读写职责。
- Add / Remove Peer:在目标节点上增加一个 Raft 副本,完成数据同步后,移除源节点副本。这才是真正的数据搬迁。
IO 路径分析
一次典型的读写请求在 TiKV 中的路径:
- Client 携带 key 向 PD 查询所属 Region 及其 Leader 地址(首次查询,后续缓存)
- Client 直接向 Region Leader 发起读写
- 如果 Region 发生了分裂或 Leader 切换,Client 的请求会收到
NotLeader或RegionNotFound错误 - Client 回 PD 刷新路由缓存,重试
对号入座:笔者认为 TiKV 处于流派天平的中间位置——
- 有集中式管理(PD),但 IO 路径对 PD 是弱依赖。PD 短暂不可用时,只要路由缓存没有过期,Client 照常读写。
- 分区粒度适中(96~144MB),比 Ceph PG 轻很多,分裂和迁移的代价可控。
- 但相比 Azure Storage 的 Extent 粒度(~1GB 且由控制节点全权分配),TiKV 的均衡精度仍有差距,且 Region 的 Raft 开销限制了 Region 不能做得太小。
注:tikv 是一种用户 kv 数据的 range 分区。很多我们的 blob 存储引擎,用户提交过来的是一个二进制,需要我们来分配 blob id。
迁移对用户 IO 的影响
数据迁移必然消耗磁盘和网络带宽。如果不加限制地全速迁移,用户请求的延迟会显著抖动。
工程手段:
- 速率限制:PD 调度器内置 rate limiter,控制同时进行的迁移任务数量和带宽上限
- 低峰调度:对非紧急的均衡操作,选择业务低峰期执行
- 优先级区分:故障修复类的迁移优先级高于普通均衡类迁移
路由与元数据管理
分区策略定下来了,还有一个绕不开的实际问题:路由信息存在哪里,客户端怎么拿到?
可计算路由
以 Ceph CRUSH 为代表。客户端持有一份 Cluster Map,本地即可计算出数据位置。
优势:IO 路径上无需额外查询,无中心瓶颈。
劣势:
- Map 变更需全局同步,过渡期存在路由不一致的窗口
- 资源均衡困难——确定性算法在物理拓扑变化时,难以做到"搬迁量最小且分布最优"的兼顾
集中式目录 + 缓存
以 TiKV PD、CubeFS Master 为代表。管理节点维护全量映射表,客户端首次查询后缓存。
缓存失效机制通常依赖版本号 / Epoch:每次分区变更(分裂、迁移)都会递增 Epoch。Client 请求携带 Epoch,Server 发现过期则返回错误,Client 回管理节点更新缓存。
优势:灵活,分区变更对客户端几乎透明。
劣势:管理节点成为关键路径的一部分(虽然通过缓存大幅削弱了依赖程度)。
管理节点的高可用
无论哪种方案,管理节点自身的高可用都是不可忽视的。常见做法:
- 管理节点自身通过 Raft/Paxos 做多副本
- 读路由操作允许 Follower 响应(如 PD Follower Read),减轻 Leader 压力
- 极端设计中将 TSO(时间戳分配)和路由查询分离部署,各自独立扩展
热点与负载均衡
数据分布均匀不等于负载均匀。同一批数据,昨天还无人问津,今天就可能被疯狂访问。
热点来源:
- 数据分布不均(Range 分区的单调递增写入)
- 访问模式倾斜(某个 key 或某段 key 范围突发高流量)
应对手段:
| 场景 | 策略 | 说明 |
|---|---|---|
| 写热点 | 分裂热点分区 | 将负载拆分到两个分区的两个 Leader 上 |
| 写热点 | Key 打散 | 业务侧对 key 加随机前缀/后缀,牺牲范围查询换取均匀分布 |
| 读热点 | Follower Read | 允许读请求访问 Follower 副本,分摊 Leader 压力。但需要注意一致性。 |
| 读热点 | 副本扩展 | 临时增加热点分区的副本数 |
| Leader 集中 | Transfer Leader | PD 将 Leader 均匀打散到各节点 |
值得一提的是,静态路由流派处理热点的手段相对有限——PG 粒度太粗,打散困难。这也是动态路由流派在需要精细 QoS 的场景中占优的原因之一。
分区与事务
分区带来了一个副作用:数据被拆散到了不同的复制组里。
如果一个事务只涉及单个分区内的数据,那很简单——在一个 Raft Group 内完成,天然具备原子性和隔离性。
一旦事务跨越了多个分区,就不得不引入分布式事务协议(2PC、Percolator 等)。代价是延迟更高、失败概率更大、实现复杂度显著上升。
这意味着分区策略的设计会直接影响上层事务的性能。一条实用经验:尽量让经常一起访问的数据落在同一个分区中。比如 TiDB 中对同一张表的数据默认按主键 Range 分区,保证了相邻行在同一 Region 内。
关于分布式事务的具体协议和实现,超出了本节范畴。分布式事务是非常复杂的,是 tidb 这类基于分布式 kv 系统构建数据库的基石。分布式事务适合更上层的系统语义设计范畴,本节不展开展开讨论。
工业系统对照
| 系统 | 流派 | 分区单元 | 映射方式 | 分裂/迁移 | 元数据管理 | 管理节点依赖 |
|---|---|---|---|---|---|---|
| Ceph | 静态路由 | PG | CRUSH 可计算 | PG 分裂(少见) | Monitor (Paxos) | 弱 |
| GlusterFS | 静态路由 | Brick | DHT Hash | 手动 rebalance | 无中心 | 无 |
| TiKV | 折中 | Region (~96MB) | PD 集中目录 | 自动分裂/合并 | PD (Raft) | 中 |
| CubeFS | 折中 | DataPartition (~120GB) | Master 目录 | 动态分裂 | Master (Raft) | 中 |
| Azure Storage | 动态路由 | Extent (~1GB) | 控制节点分配 | 全自动 | Partition Master | 强 |
| Pangu | 动态路由 | Chunk | 控制节点分配 | 全自动 | Master (Raft) | 强 |
小结
| 类别 | 具体类型 | 核心特征 | 核心优势 | 核心劣势 |
|---|---|---|---|---|
| 流派 | 静态路由 | 客户端本地计算,管理节点旁路 | 无中心瓶颈,管理面故障不影响 IO | 均衡粗糙,迁移笨重 |
| 动态路由 | 控制节点全权分配 | 极致灵活,精细均衡,编码转换易 | 强依赖管理节点可用性 | |
| 映射 | Hash / 一致性哈希 | 可计算,均匀 | 无需目录服务 | 不支持范围查询 |
| Range | 按 key 范围划段 | 支持范围扫描 | 热点倾斜 | |
| CRUSH | 伪随机可计算 | 无中心,感知故障域 | 均衡受拓扑限制 | |
| 控制节点分配 | 实时决策 | 均衡精度最高 | 管理节点为关键路径 | |
| 生命周期 | 分裂 | 分区过大/过热时一分为二 | 解决热点和容量问题 | Raft Group 增多,开销增大 |
| 合并 | 相邻小分区合一 | 减少元数据和心跳开销 | 协调复杂 | |
| 迁移 | 副本在节点间搬运 | 实现负载均衡 | 消耗带宽,影响前台 IO |
分区策略没有银弹。笔者的理解是,它本质上是元数据复杂度、迁移代价、调度精度之间的三方博弈。静态路由在管理面极简上做到了极致,动态路由在调度灵活度上做到了极致。大多数系统落在中间某处,根据自身的业务场景和团队能力做取舍。
继续阅读
- 《设计数据密集型应用》3 “分区"章节提供了更全面的分区理论。(笔者建议带着具体系统的设计问题去读,否则容易流于概念而难以体会动机。)
- Ceph 的 CRUSH 算法论文4详述了可计算放置的设计与评估。
- Azure Storage 论文5 的 Stream Layer 部分描述了控制节点动态分配的完整设计。
- TiKV 官方文档6中有 PD 调度策略的详细描述。
参考文献
-
对于 append-only 底座,已经打开写入的 Extent 通常会被 seal(封口),停止接受新写入。管理节点不可用时,已 seal 的数据仍可正常读取,影响的主要是新的写入分配。 ↩︎
-
DeCandia, Giuseppe, et al. “Dynamo: Amazon’s Highly Available Key-value Store.” SOSP'07. ↩︎
-
Weil, Sage A., et al. “CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data.” SC'06. ↩︎
-
Calder, Brad, et al. “Windows Azure Storage: A Highly Available Cloud Storage Service with Strong Consistency.” SOSP'11. ↩︎